


#Day10 - Data Layout (Row-Based vs Column-Based)
A series of posts to understand databases better

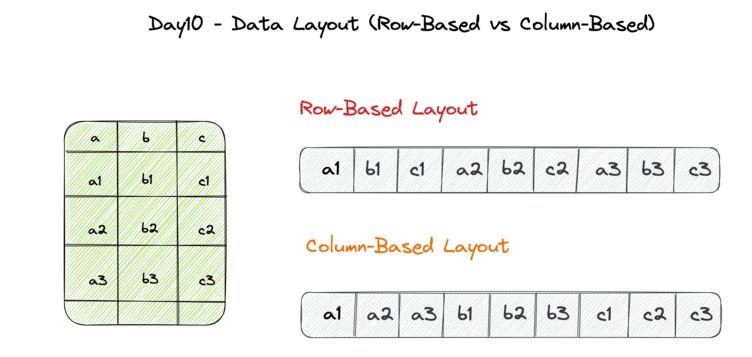
Before we dive deeper into the different data layouts on disk, it is important to understand the various data layout patterns. In a database, there are different ways in which data is written to disk, including row-based and column-based data layout.
Row-based storage: In row-based storage, data for a single row of a table is stored together in one block or page on disk. This means that all the columns of a given row are stored together, which can make it efficient for operations that need to retrieve an entire row of data at once, such as SELECT queries. However, row-based storage can be less efficient for operations that only need to access a subset of the columns in a table.
Column-based storage: In column-based storage, each column of a table is stored separately on disk, which means that all the values for a given column are stored together. This can be more efficient for operations that only need to access a subset of the columns in a table, as the database can avoid reading in unnecessary data. Column-based storage can also be more efficient for certain types of queries, such as those that involve aggregations or calculations that only involve one column.
Hybrid storage: Some databases use a hybrid storage approach that combines both row-based and column-based storage. In this approach, the database may store frequently accessed columns in a column-based format and less frequently accessed columns in a row-based format. This can provide the benefits of both approaches, but can also be more complex to implement and manage.
Compressed (or Block Compressed) storage: Databases can also use compression techniques to reduce the amount of data that needs to be written to disk. For example, the database may use a compression algorithm to reduce the size of data before writing it to disk, and then decompress it when reading it back into memory. This can help to save disk space and reduce I/O operations, but can also add some overhead to the database's processing.
Row-Oriented Data Layout

Row-based storage algorithms work by storing the data for each row of a table together in a block or page on disk. When a database needs to read or write a row of data, it reads or writes the entire block that contains the row.
Here's an example of how a row-based storage algorithm might work:
Suppose we have a table with the following columns: "ID", "Name", "Age", and "Address". Each row of the table contains a unique ID, along with the name, age, and address of a person.
With row-based storage, the data for each row of the table is stored together in a block or page on disk. For example, the first row might be stored in a block that contains the following data:
ID | Name | Age | Address
1 | John | 30 | 123 Main Street
The second row might be stored in a block that contains the following data:
ID | Name | Age | Address
2 | Mary | 25 | 456 Elm Street
When the database needs to read a row of data, it reads the entire block that contains the row. For example, if we want to retrieve the data for the row with ID 1, the database would read the block that contains that row, which includes all the columns of the table.
Similarly, when the database needs to write a row of data, it writes the entire block that contains the row. For example, if we want to update the age of the person with ID 1, the database would write the entire block that contains that row, including the updated age.
Row-based storage can be efficient for operations that need to retrieve or update entire rows of data, but can be less efficient for operations that only need to access a subset of the columns in a table. Column-based storage can be more efficient for those types of operations.
Column-Oriented Data Layout

Column-based storage algorithms store data by organizing it into columns, rather than rows. In a column-based storage model, each column is stored separately on disk, with all values for that column grouped together. This allows for more efficient and selective access to data, as queries can be optimized to only access the columns needed for a particular operation.
When a new row is added to the database in a column-based storage system, the values for each column are added to the appropriate column files. This means that the same column file can be updated independently of the other columns, which can result in better write performance in certain situations. Additionally, because column data is stored together, it can be compressed more efficiently, reducing the amount of storage required on disk.
In order to retrieve data from a column-based storage system, a query is executed that specifies which columns are needed for the operation. The system retrieves only the relevant columns from disk, rather than retrieving the entire row as in a row-based storage system. This can result in faster query performance and reduced I/O overhead.
A popular example of a column-based storage algorithm is Apache Cassandra, which is a highly scalable and distributed database system used by many large companies, such as Netflix and Twitter.
In Cassandra, data is stored in a distributed fashion across multiple nodes, and each node stores data in a column-family format, which is a collection of columns. Within each column family, columns are stored separately on disk, with all values for a particular column stored together. Each column can have its own sorting and indexing, which enables highly efficient and selective access to data.
When new data is added to a column family, the values for each column are added to the appropriate column file on disk. This means that the same column file can be updated independently of the other columns, which can result in better write performance in certain situations. Additionally, because column data is stored together, it can be compressed more efficiently, reducing the amount of storage required on disk.
Wide-column stores
Column-oriented databases are not similar to wide column stores, such as BigTable or HBase, where data is stored using a column-family data model. In a wide column store, data is organized into column families, which are sets of columns that are related to each other. Each column family can have a different set of columns, and each column can have a different data type. This layout is best for storing data retrieved by a key or a sequence of keys.
The data in a wide column store is stored in rows, with each row identified by a unique row key. Within each row, the data is stored in columns, with each column identified by a column name. The values of the columns can be of different data types, such as strings, integers, or binary data.
One of the key features of wide column stores is their ability to scale horizontally across multiple nodes, which makes them well-suited for handling large volumes of data. They also support flexible schema designs, as the data model can be easily adapted to changing requirements without requiring a schema migration.
Examples of wide column stores include Apache Cassandra, Apache HBase, and Amazon DynamoDB. They are commonly used in applications such as real-time analytics, high-traffic web applications, and large-scale content management systems.
Pros vs Cons
Row-oriented databases and column-oriented databases have their own pros and cons. I listed a few here that can hopefully help you make a decision.
Row-based and column-based storage are two different approaches to storing data in a database. Each approach has its own advantages and disadvantages, which can make one more suitable than the other depending on the specific use case. Here are some of the key pros and cons of each approach:
Row-based storage:
Pros:
Best suited for OLTP applications.
Works well for transactional workloads where data is frequently updated, as each row is stored contiguously on disk and can be easily updated in-place.
Good for accessing entire records, as all columns are stored together in each row.
Generally easier to understand and work with for developers and DBAs.
Cons:
Can be inefficient for analytical workloads where queries only need to access a subset of columns from a large table, as all columns must be read even if only a few are needed.
Can lead to I/O inefficiencies if the table contains a large number of columns, as reading an entire row can result in reading many unneeded columns.
Can be less efficient for compressing data, as each row may contain many columns with repeated values.
Column-based storage:
Pros:
Best suited for OLAP application.
Efficient for analytical workloads, as queries can be designed to read only the columns needed for the analysis, reducing I/O and improving query performance.
Can be more efficient for compressing data, as repeated values in each column can be easily identified and stored more compactly.
Good for handling large data sets, as only the needed columns are read, reducing the amount of data read from disk.
Cons:
Can be less efficient for transactional workloads where data is frequently updated, as each column is stored separately and must be updated in multiple locations.
Can be more complex to manage and understand for developers and DBAs, as data is stored across multiple columns.
Can be less efficient for accessing entire records, as each column must be read separately and assembled into a row.
Row-based storage is well-suited for transactional workloads with small to medium-sized tables, while column-based storage is better for analytical workloads with large tables and complex queries that access a subset of columns.
We will dive deeper into the data layout in the next article.
#database #sql #algorithms #systemdesign #datastructures #sql #nosql
