
ART: Building a Prefix Search Trie in Go

Have you ever wondered how search queries in databases work so fast? Indexes you may say. And how do indexes work under the hood? Trees (Tries) you affirm.

TLDR, ART increased performance of my database 2x when compared to a skiplist. The code for an Adaptive Radix Trie (ART) implemented by me is below.
The Need
I was in search of a data structure to support prefix searches for keys in a Redis like in-memory store that I'd made called FlashDB. Currently, string key-value pairs were stored on the backend as a skip list. The design choice was not the best, but to support fast query speed and prefix searches, I assumed ordering the keys in lexical order would be helpful. It wasn't efficient and the benchmarks showed the performance of simple key-value searches would be very slow.
The algorithms behind search engines are nearly countless. The most common one used is a prefix tree, also known as a Trie. Tries are used for building key-value stores and indexes, after search trees (like B-trees and red-black trees) and hash tables.
The Search
There are 3 kinds of data structures to maintain indexes in memory.
Binary tree: T tree is old and not optimized for modern CPU architecture. B+ tree is more cache-friendly but tempers with the predictive comparison from modern CPU. FAST is great for modern CPU architectures, but it does not support incremental updates.
Hash table: Efficient in memory indexes but only support single-point queries. Updates and deletion can be expensive when they require reorganising the hash table.
Tries: Have a number of very appealing properties - for example, the height of a trie is independent of the number of keys it contains, and a trie requires no rebalancing when updated. The complexity of tries grows with the length of the key, not the number of elements in the structure. They suffer bad space performance when the keys are sparse.
Paper Trail had published this interesting article long back on optimised Radix Tries. Radix Tries have good properties like:
Complexity depends on key length, not the number of elements
There no need for rebalancing: two different insert orders result in the same tree
Keys are store in lexicographical order
Keys are implicitly stored in the path
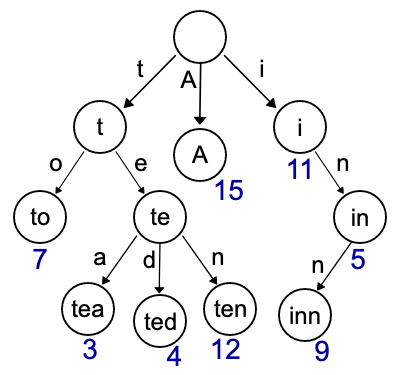
What’s wrong with ordinary tries?
Let’s imagine how we might implement a trie, as simply as we can. A single node in a trie corresponds to a key prefix; a sequence of characters that is a prefix of one or more keys in the tree. But we know what its prefix is by the path we took to get to it, so we don’t need to store it. All we need is a way to find its children.
To find the children, we need to know how to get to all the nodes that represent key prefixes one character longer than the current one, and that’s what the children array is for. Here we’re assuming an 8-bit alphabet, with 256 possible characters per letter, or a fan-out of 256.
The paper calls the width of a single character the span of the trie, and it’s a critical parameter as it determines a trade-off between the fan-out of each node, and the height of the trie, since if you can pack more of a value into a single node by having a larger span, you need fewer nodes to describe the whole string.
The problem, as you can no-doubt see, is that there’s a possibility of a lot of wasted space in each node. Imagine a radix trie containing foo, fox and fat. The root node would have one valid pointer, to f, which would have two valid pointers, to a and o. a would have a pointer to t, and o would have pointers to o and x.
So our trie would have 6 nodes, but a total of 6 * 26 = 156 pointers, of which 150 / 156 = 96% are empty and therefore wasted space! At 8-bytes per pointer, that’s already over 1K wasted space to store just 9 bytes of information.
The paper introduces ART, an adaptive radix tree (trie) for efficient indexing in main memory. It quotes the lookup performance surpasses highly tuned, read-only search trees, while supporting very efficient insertions and deletions as well. At the same time, ART is very space efficient and solves the problem of excessive worst-case space consumption, which plagues most radix trees, by adaptively choosing compact and efficient data structures for internal nodes. It maintains the data in sorted order, which enables additional operations like range scan and prefix lookup.
Perfect! Now time to implement it.
The Implementation
ART uses 3 techniques to make radix tree a viable option:
Dynamic node size
Path compression
Lazy expansion
Dynamic node size
Inner nodes of the radix tree use a "span" s, they store 2^s pointers. So for a k-bit key, the height of the tree is k/s. Radix trees are smaller than binary trees if the number of elements n is n > 2^(k/s). For pure lookups, a higher span is better. But space usage is bad because most of the pointers are nulls.
ART uses a large span with different fanouts. When inserting, if the node is too small, it is replaced by a larger one. If underfull, the node is replaced with a smaller one.
They use a span of 8 bits to ease the implementation (the radix tree used in Linux uses a 6 bits span). Because changing the fanout of the node for every update operation would be counterproductive, They choose 4 different node sizes:
Node4is the smaller inner node, it contains a maximum of 4 children nodes stored as arraysNode16is a largerNode4. For efficient lookup, it can use SIMD operationsNode48uses an indirection layer to store children nodeNode256uses a single array of2^span = 256length
func newNode4() *Node {
in := &innerNode{
nodeType: Node4,
keys: make([]byte, Node4Max),
children: make([]*Node, Node4Max),
meta: meta{
prefix: make([]byte, MaxPrefixLen),
},
}
return &Node{innerNode: in}
}
func newNode16() *Node {
in := &innerNode{
nodeType: Node16,
keys: make([]byte, Node16Max),
children: make([]*Node, Node16Max),
meta: meta{
prefix: make([]byte, MaxPrefixLen),
},
}
return &Node{innerNode: in}
}
func newNode48() *Node {
in := &innerNode{
nodeType: Node48,
keys: make([]byte, Node256Max),
children: make([]*Node, Node48Max),
meta: meta{
prefix: make([]byte, MaxPrefixLen),
},
}
return &Node{innerNode: in}
}
func newNode256() *Node {
in := &innerNode{
nodeType: Node256,
children: make([]*Node, Node256Max),
meta: meta{
prefix: make([]byte, MaxPrefixLen),
},
}
return &Node{innerNode: in}
}Path compression
If the sequence of single-child nodes does not end in a leaf, ART uses path compression. This collapses the sequence of nodes, but into the node at the end of the sequence that has more than one child. That is, consider inserting CAST and CASH into an empty trie; path compression would create a node at the root that has the CAS prefix, and two children, one for T and one for H. That way the trie doesn’t need individual nodes for the C->A->S sequence.
Lazy expansion

Two techniques are described that allows the trie to shrink its height if there are nodes that only have one child. They reduce the impact of having either strings with a unique suffix (lazy expansion) or a common prefix (path compression). Figure 6 in the paper illustrates both techniques clearly.
func (n *Node) shrink() {
in := n.innerNode
switch n.Type() {
case Node4:
c := in.children[0]
if !c.IsLeaf() {
child := c.innerNode
currentPrefixLen := in.prefixLen
if currentPrefixLen < MaxPrefixLen {
in.prefix[currentPrefixLen] = in.keys[0]
currentPrefixLen++
}
if currentPrefixLen < MaxPrefixLen {
childPrefixLen := min(child.prefixLen, MaxPrefixLen-currentPrefixLen)
copyBytes(in.prefix[currentPrefixLen:], child.prefix, childPrefixLen)
currentPrefixLen += childPrefixLen
}
copyBytes(child.prefix, in.prefix, min(currentPrefixLen, MaxPrefixLen))
child.prefixLen += in.prefixLen + 1
}
replaceNode(n, c)
case Node16:
n4 := newNode4()
n4in := n4.innerNode
n4in.copyMeta(n.innerNode)
n4in.size = 0
for i := 0; i < len(n4in.keys); i++ {
n4in.keys[i] = in.keys[i]
n4in.children[i] = in.children[i]
n4in.size++
}
replaceNode(n, n4)
case Node48:
n16 := newNode16()
n16in := n16.innerNode
n16in.copyMeta(n.innerNode)
n16in.size = 0
for i := 0; i < len(in.keys); i++ {
idx := in.keys[byte(i)]
if idx > 0 {
child := in.children[idx-1]
if child != nil {
n16in.children[n16in.size] = child
n16in.keys[n16in.size] = byte(i)
n16in.size++
}
}
}
replaceNode(n, n16)
case Node256:
n48 := newNode48()
n48in := n48.innerNode
n48in.copyMeta(n.innerNode)
n48in.size = 0
for i := 0; i < len(in.children); i++ {
child := in.children[byte(i)]
if child != nil {
n48in.children[n48in.size] = child
n48in.keys[byte(i)] = byte(n48in.size + 1)
n48in.size++
}
}
replaceNode(n, n48)
}
}
Alternatively, the node can also grow as required when the children are more than the maximum keys a node can hold.
func (n *innerNode) grow() {
switch n.nodeType {
case Node4:
n16 := newNode16().innerNode
n16.copyMeta(n)
for i := 0; i < n.size; i++ {
n16.keys[i] = n.keys[i]
n16.children[i] = n.children[i]
}
replace(n, n16)
case Node16:
n48 := newNode48().innerNode
n48.copyMeta(n)
index := 0
for i := 0; i < n.size; i++ {
child := n.children[i]
if child != nil {
n48.keys[n.keys[i]] = byte(index + 1)
n48.children[index] = child
index++
}
}
replace(n, n48)
case Node48:
n256 := newNode256().innerNode
n256.copyMeta(n)
for i := 0; i < len(n.keys); i++ {
child := (n.findChild(byte(i)))
if child != nil {
n256.children[byte(i)] = *child
}
}
replace(n, n256)
case Node256:
}
}The Prefix Search Method
// Prefix Scan
tree.Insert([]byte("api"), "bar")
tree.Insert([]byte("api.com"), "bar")
tree.Insert([]byte("api.com.xyz"), "bar")
leafFilter := func(n *art.Node) {
if n.IsLeaf() {
fmt.Println("value=", string(n.Key()))
}
}
tree.Scan([]byte("api"), leafFilter)
The Benchmarks
I tested loading a dictionary of 235886 words into each tree. Here are the results.
// ART tree
BenchmarkWordsArtTreeInsert-16 14 79622476 ns/op 46379858 B/op 1604123 allocs/op
BenchmarkWordsArtTreeSearch-16 43 28123512 ns/op 0 B/op 0 allocs/op
// Radix tree
BenchmarkWordsRadixInsert-16 12 96886770 ns/op 50057340 B/op 1856741 allocs/op
BenchmarkWordsRadixSearch-16 33 40109553 ns/op 0 B/op 0 allocs/op
// Skiplist
BenchmarkWordsSkiplistInsert-16 4 271771239 ns/op 32366958 B/op 1494019 allocs/op
BenchmarkWordsSkiplistSearch-16 8 135836216 ns/op 0 B/op 0 allocs/opHow did it improve flashdb? Well, almost twice as fast! Here are the benchmarks for the string store:
Skip list
BenchmarkFlashDBPutValue64B-16 159992 7208 ns/op 1461 B/op 19 allocs/op
BenchmarkFlashDBPutValue128B-16 175634 9499 ns/op 2003 B/op 19 allocs/op
BenchmarkFlashDBPutValue256B-16 148362 9278 ns/op 3322 B/op 19 allocs/op
BenchmarkFlashDBPutValue512B-16 120865 16542 ns/op 6037 B/op 19 allocs/op
BenchmarkFlashDBGet-16 1881042 643.9 ns/op 32 B/op 2 allocs/op
ART Trie
BenchmarkFlashDBPutValue64B-16 204318 5129 ns/op 1385 B/op 19 allocs/op
BenchmarkFlashDBPutValue128B-16 231177 5318 ns/op 1976 B/op 16 allocs/op
BenchmarkFlashDBPutValue256B-16 189516 6202 ns/op 3263 B/op 15 allocs/op
BenchmarkFlashDBPutValue512B-16 165580 8110 ns/op 5866 B/op 16 allocs/op
BenchmarkFlashDBGet-16 4053836 294.9 ns/op 32 B/op 2 allocs/op